
Scritto da Martina Fieromonte (Area Valorizzazione Dati RES)
L’ultimo step di pre-processamento per il Natural Language Processing (NLP) consiste nella creazione di un modello di rappresentazione dei dati. Punto cruciale di tale processo è la trasformazione dei dati testuali, tipici del contesto NLP, in un formato processabile dagli algoritmi, nello specifico numeri e vettori.
Nelle sezioni successive si approfondiranno, quindi, le sfide poste dalla rappresentazione dei dati testuali, anche noti come dati categorici, i principali modelli di rappresentazione per questo tipo di dati, applicabilità, punti di forza e criticità di tali metodi per i diversi task NLP.
Indice degli argomenti
Data Representation: la codifica dei dati categorici
Come abbiamo visto in articoli precedenti, i dati che popolano il mondo del Natural Language Processing (NLP) sono dati testuali, stringhe, caratteri, categorie, in una parola, dati categorici:
Sono esempi di dati categorici
- I nomi delle persone: Mario, Lucia, Francesca
- Le città in cui un individuo vive: Roma, Londra, New York
- I posti in classifica degli atleti in una gara: primo, secondo, terzo, ecc.
Tali dati richiedono una “trasformazione” in valori numerici prima di poter essere utilizzati per il Machine Learning (ML). Infatti, quasi tutti gli algoritmi di ML, molto efficienti con i dati numerici, non riescono a processare dati in formato testuale.
Esiste, inoltre, un’ulteriore differenza all’interno dei dati categorici che è buona prassi considerare per un’accurata scelta delle successive strategie di rappresentazione. Le variabili categoriche ordinali (vedi esempio del posto in classifica ottenuto dagli atleti) presentano un ordinamento al proprio interno che in fase di codifica deve essere necessariamente considerato. Nell’esempio proposto, infatti, il più alto posto in classifica dà indicazioni sul vincitore e su altri possibili atleti qualificati.
I dati dei primi due esempi dell’elenco puntato sono, invece, definiti variabili categoriche nominali poiché prive di un ordine interno. Nel caso dei dati nominali, è necessario considerare la presenza o l’assenza di qualche particolare caratteristica. Non è presente nessun ordine o sequenza, e di fatti, non fa nessuna differenza se una persona vive a Roma o a Napoli (esempio 2).
Da queste premesse si evince che conoscere il tipo di dati categorici con cui si sta lavorando e il tipo di task NLP che si vuole portare a termine costituisce un fattore determinante nella scelta del miglior metodo di rappresentazione dei dati.
Dal testo ai numeri: un tour tra i metodi di rappresentazione dei dati per il NLP
In questo paragrafo sono presentati i principali metodi di rappresentazione dei dati. Partendo dal Label Encoding, una delle tecniche più immediate per rappresentare le variabili ordinali, si illustrano i diversi metodi di rappresentazione della controparte nominale. Nello specifico, sono presentati i principi di funzionamento dei metodi Bag of Words, Word Embedding e Embedding Contestualizzati o Dinamici corredati dai principali punti di forza, dai loro limiti e applicabilità ai diversi task NLP.
Label Encoding
Il Label Encoding permette di gestire le variabili categoriche ordinali e consiste nell’assegnazione di un numero intero alla variabile. Riprendendo l’esempio della gara sportiva:
primo = 1; secondo = 2; terzo = 3
A questo punto, sintetizzando, il computer sarà capace di gestire i dati poiché in formato numerico.
One-hot-encoding via Bag of Words (BoW)
Applicando la tecnica del Label Encoding ai dati nell’esempio “città di residenza”, quindi a variabili nominali, si otterrebbero i seguenti valori:
Roma = 1, Londra = 2, New York = 3
Tuttavia, se si chiedesse all’algoritmo di fornire la media dei dati, questa risulterebbe essere 2, quindi Londra. Il motivo di ciò è che l’algoritmo cercherebbe di interpretare i dati come se essi contenessero qualche tipo di ordine/gerarchia. Come si è visto sopra, questo non vero per le variabili nominali.
Per trattare questo tipo di variabili si preferisce utilizzare un metodo binario, noto come One-Hot-Encoding (OHE). Tramite questa tecnica, alle variabili è possibile assegnare solo due valori: 0 e 1. In particolare l’assegnazione del valore 0 indica l’assenza di una caratteristica nei dati, mentre l’assegnazione del valore 1, la sua presenza.
All’interno dei metodi OHE per il NLP, ha avuto rilevanza e continua ad averla ancora oggi il modello Bag of Words (BoW). Si tratta del modello più semplice e immediato per convertire i testi in vettori (un elemento matematico che ha un valore numerico, una direzione e una posizione in uno spazio). Come dice il nome stesso, il modello porta ad una rappresentazione del testo come una “borsa” di vettori delle parole.
Date per esempio tre frasi, in questo caso, tre recensioni ad un libro
Recensione 1: Questo libro è molto spaventoso e lungo.
Recensione 2: Questo libro non è spaventoso e non è monotono.
Recensione 3: Questo libro è accattivante e bello.
si costruisce un vocabolario di tutte le parole presenti nelle recensioni. Quindi: ‘questo’, ‘libro’, ‘è’, ‘molto’, ‘spaventoso’, ‘e’, ‘lungo’, ‘non’, ‘monotono’, ‘accattivante’, ‘bello’. In seguito, si marca con 1 la presenza e con 0 l’assenza delle parole del vocabolario nelle recensioni. In questo modo si ottiene una matrice (in matematica una tabella di valori ordinati), le cui righe (che riportano i valori 0 e 1 assegnati ad ogni recensione), costituiscono la rappresentazione vettoriale di quella determinata recensione.
| 1 Questo |
2 libro |
3 è |
4 molto |
5 spaventoso |
6 e |
7 lungo |
8 non |
9 monotono |
10 accattivante |
11 bello |
n.parole per recensione | |
| Recensione 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 7 |
| Recensione 2 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 9 |
| Recensione 3 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 6 |
Vettore per Recensione 1: [1,1,1,1,1,1,1,0,0,0,0]
Vettore per Recensione 2: [1,1,1,0,1,1,0,1,1,0,0]
Vettore per Recensione 3: [1,1,1,0,0,1,0,0,0,1,0]
Il BoW non è l’unico modello appartenente alla famiglia OHE. Molto conosciuto è anche il metodo TF-IDF (Term Frequency-Inverse Document Frequency) in cui la rilevanza di una parola all’interno di una raccolta di documenti è basata sulla sua bassa frequenza.
Essendo capace di tracciare la presenza di termini all’interno di un corpus, il modello BoW è stato utilizzato, e lo è ancora, in diversi task NLP, come la classification dei testi, il tagging grammaticale, lo stemming e la lemmatizzazione. Tuttavia tale metodica presenta alcuni svantaggi. L’inserimento di nuove frasi nel corpus potrebbe implicare un aumento della grandezza del vocabolario e, conseguentemente, della lunghezza dei vettori. Di fatti, ogni osservazione, nel nostro caso ogni recensione, avrà un numero di valori per vettore pari alle parole del vocabolario. Molti di questi valori sarebbero degli 0 e ciò darebbe vita ad una matrice sparsa, la cui rappresentazione comporterebbe una grande quantità di memoria.
Inoltre, il BoW non fornisce informazioni riguardo la grammatica, la posizione e soprattutto il significato di una parola. Questa mancanza rappresenta un problema non indifferente nella progettazione di modelli e applicazioni sempre più sensibili alle specificità del linguaggio umano. Si pensi ai task di similarità tra parole o frasi. Il modello BoW, trascurando la posizione di una parola e il suo significato, non dà peso a delle informazioni che, se ben modellate, potrebbero fare la differenza per questo task.
Word Embedding
Che il BoW non includa una nozione diretta di significato lo si evince dal seguente esempio:
- Se un utente web digitasse la query “Capacità batteria notebook Asus”, questo si aspetterebbe che i risultati di ricerca includano anche documenti in cui è presente l’espressione “Capacità batteria pc Asus”. Le due query hanno, infatti, pressoché un significato identico.
|
query 1 ——— query 2 |
capacità
———- [ 1 ———- [ 1 |
batteria
———- 1 ———- 1 |
notebook
———— 1 ———— 0 |
pc
— 0 — 1 |
Asus
——- 1 ] ——- 1 ] |
Tuttavia se il motore di ricerca si basa sul metodo BoW, le due query verrebbero rappresentate da vettori diversi (vedi tabella). Di conseguenza, la prima query non includerebbe, indirettamente, la seconda. |
Il Word Embedding (WE) si presenta come un modello capace di ovviare a questi e simili problemi tipici della rappresentazione BoW. Si tratta di un modello di codifica del testo in cui i vettori delle parole semanticamente simili si trovano più vicini all’interno di uno spazio definito. Ne consegue che parole con un significato simile avranno una rappresentazione vettoriale simile.
Alla luce di queste considerazioni, un modello di rappresentazione WE sarebbe capace di comprendere che “notebook” e “pc” hanno un significato molto simile e che le frasi precedenti che contengono queste due parole possono, a loro volta, essere considerate simili.
L’essenza del word embedding è ispirata dalla teoria linguistica della Semantica Distribuzionale, secondo cui è più facile comprendere il significato di una parola basandosi sul suo contesto, ovvero sulle parole che le stanno vicino:
“You shall know a word by the company it keeps!” (J.R.Firth)
Dal punto di vista di rappresentazione dell’informazione, invece, alla base del WE vi è il concetto di rappresentazione distribuita, dove l’informazione associata ad una determinata entità si distribuisce sull’intera rete di entità, in questo caso sulle entità che fanno parte del contesto della parola. Questo concetto si pone in opposizione alla rappresentazione localista in cui la rappresentazione dell’informazione associata all’entità viene restituita in uno slot unico e indipendente.
Ogni parola nel metodo WE è rappresentata da un vettore di valori numerici reali, a bassa dimensionalità che dà vita ad una matrice densa, una matrice che contiene pochi valori 0. A differenza del modello BoW, i vettori non avranno la lunghezza del vocabolario della raccolta, ma di un numero di dimensioni stabilito in fase di implementazione.
Come funzionano i word embedding? I metodi WE apprendono i valori da assegnare ai vettori da un vocabolario predefinito estratto da un corpus. Il processo di apprendimento è simile a quello delle reti neurali artificiali, modelli di apprendimento che tramite una rete di connessioni tra gli elementi al loro interno riescono a compiere un task automaticamente.
Uno dei più classici e chiari esempi per spiegare il modello WE prevede l’utilizzo delle coppie di termini uomo-donna, re-regina. La tabella sottostante riporta i valori assegnati da un ipotetico modello WE:
| uomo | donna | re | regina | |
| dimensione 1 (genere?) | 1 | -1 | 0.95 | -0.95 |
| dimensione 2 (nobiltà?) | 0.02 | 0.03 | 0.98 | 0.97 |
Ogni dimensione (anche embedding) rappresenta una caratteristica delle parole che viene stimata in termini di numeri reali. Quale sia la caratteristica individuata non è possibile dirlo con certezza (è così che funzionano le reti neurali). In base ai valori assegnati ai dati, è possibile però fare delle ipotesi: si può assumere che il primo embedding codifichi il genere della parola e il secondo la nobiltà. Tale constatazione sembrerebbe avere senso se si osservano:
- i valori opposti assegnati a parole appartenenti a generi diversi (donna-regina, uomo-re);
- i valori che codificano la nobiltà, prossimi allo 0 nella coppia uomo-donna (in quanto parole prive di una connotazione di nobiltà), tendenti, invece, a 1 nella coppia re-regina.
Trasliamo sul piano grafico i risultati del modello
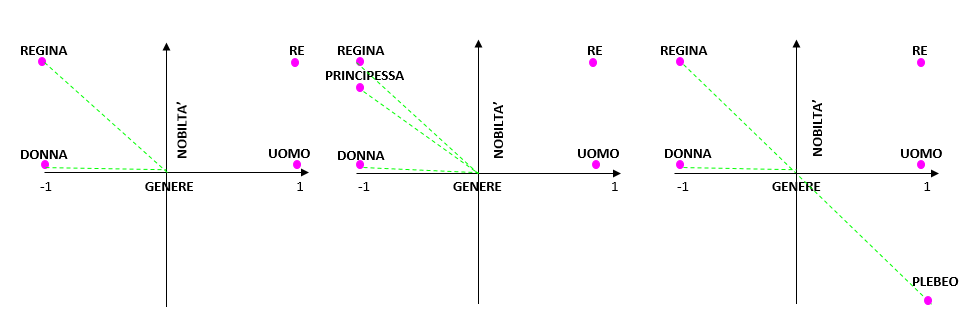
Molto chiaramente è possibile osservare come parole simili condividano lo stesso spazio e si trovino quindi più vicine. Al contrario, parole opposte semanticamente vengono rappresentate in punti opposti del piano (regina-plebeo).
Word2vec
Il Word2vec, sviluppato da Tomas Mikolov et al. nel 2013, rappresenta uno dei modelli più efficienti per apprendere l’embedding di una parola. Il word2vec sfrutta due principali algoritmi per determinare l’embedding:
- il modello Continuous Bag of Words (CBOW) capace di predire una parola basandosi sul contesto.
- il modello Continuous Skip Gram capace di predire il contesto di una parola data la parola.
Entrambi i metodi apprendono l’embedding di una parola dal contesto che la circonda, che è a sua volta definito da un numero configurabile di parole vicine.
Word Embedding contestualizzati e dinamici
I modelli Word Embedding Contestualizzati o Dinamici sono stati sviluppati con l’intento di superare uno dei limiti più grandi dei modelli WE tradizionali: l’incapacità di gestire l’ambiguità del linguaggio umano. Una parola può avere, infatti, significati diversi che possono essere determinati attraverso il contesto. Si pensi alla parola “tavola” negli esempi seguenti:
- Apparecchia la tavola.
- Ho comprato una tavola da surf.
I WE tradizionali come il word2vec hanno infatti un vocabolario di parole a cui corrisponde un determinato set di embedding. Quindi, data una parola, i suoi embedding risulteranno essere sempre gli stessi, indipendentemente dalla frase in cui essa si trova. I WE tradizionali possono definirsi, essenzialmente, statici.
Contrariamente, i modelli a embedding contestualizzati non assegnano alle parole un embedding fisso, ma guardano prima al contesto di tutta la frase e poi, in base a questo, assegnano alla parola l’embedding che è più adatto a quel contesto. Esempi tipici di embedding dinamici sono ELMO e BERT. Anche qui è presente un vocabolario di parole, ma queste non contengono i rispettivi embedding, i quali vengono, invece, generati in seguito al processamento dell’intera frase.
Considerazioni finali
L’articolo ha presentato i principali modelli di rappresentazione del testo per il Natural Language Processing. Volutamente si sono tralasciati gli aspetti più “pratici” della questione, come l’effettiva implementazione dei vari modelli o le formule matematiche che muovono i fili, e non di certo perché li ritenessimo meno importanti.
Abbiamo, tuttavia, preferito impostare la trattazione in termini di problema posto dalla rappresentazione dei dati categorici e di evoluzione delle tecniche di risoluzione del problema, in ottica di un migliore apprendimento automatico delle specificità e sensibilità del linguaggio umano.
Sebbene l’argomento non si esaurisca con queste poche righe, esse costituiscono un valido punto di partenza per la comprensione di questo vasto e affascinante ambito dell’apprendimento automatico che, forse un po’ romanticamente, può essere visto come l’anello di congiunzione tra il mondo delle parole e quello dei numeri.