
Scritto da Annalisa Creazzo e Martina Fieromonte (Area Valorizzazione Dati RES)
La possibilità di portare avanti un task di Natural Language Processing (NLP), in ambito Machine Learning (ML), è resa possibile tanto dalla predisposizione di modelli e innovazioni tecnologiche, quanto dalla disponibilità di dati e dalla capacità di estrarre, manipolare e analizzare tali dati. Questi ultimi fattori si traducono in due fasi ben distinte dello sviluppo di un modello NLP: la creazione di una raccolta di dati e il loro preprocessamento.
Questo articolo offre una guida sulle principali tecniche di creazione di un dataset e sulla prima fase di pre processamento dati, il Data Cleaning.
Indice degli argomenti
I dati e il loro preprocessing
Sebbene il cervello sia da considerare la macchina più avanzata quando si tratta di processare, comprendere e generare il linguaggio umano, sarebbe poco oggettivo negare quanto gli avanzamenti nel campo dell’apprendimento automatico e della computazione abbiano migliorato l’interazione uomo-macchina e il processamento automatico del linguaggio umano.
In Natural Language Processing: che cos’è e come può aiutare il tuo business abbiamo già introdotto scopi, applicazioni e specifiche di questo ramo dell’Intelligenza Artificiale che si occupa del linguaggio. Ma come si arriva a sviluppare un modello capace di estrarre informazioni dal testo, tradurre una frase, predire quello che si sta per scrivere o rispondere automaticamente a delle domande?

Non si tratta di magia oscura e non c’entrano nemmeno gli alieni!
La verità è di ben altra natura: linguistica, informatica e matematica insieme. Infatti, per ogni fase del linguaggio che un modello riesce a processare ci sono dietro dei metodi matematici e computazionali che permettono tale processamento.
In ambito Machine Learning (ML), per dar vita al processo di apprendimento del linguaggio da parte delle macchine è necessario disporre, oltre che degli algoritmi, di dati. I dati costituiscono degli esempi da cui la macchina può apprendere lo svolgimento di un task (per esempio estrazione di informazioni, classificazione di parole e immagini, traduzione, ecc) e, una volta appreso, riprodurlo su dati simili. Secondo la semplice logica dell’apprendimento e della riproduzione.
La scelta dei dati, così come la costruzione di una raccolta di dati, il dataset, sono dei passaggi fondamentali nel ciclo di costruzione di un modello, capaci di incidere significativamente sulle performance di quest’ultimo. Raccogliere dati, però, non basta. Bisogna anche saperli “preparare”, in termini tecnici, preprocessare (in letteratura data preprocessing), per l’algoritmo, ovvero portarli in un formato che li renda predicibili e analizzabili dal compito NLP che stiamo per svolgere.
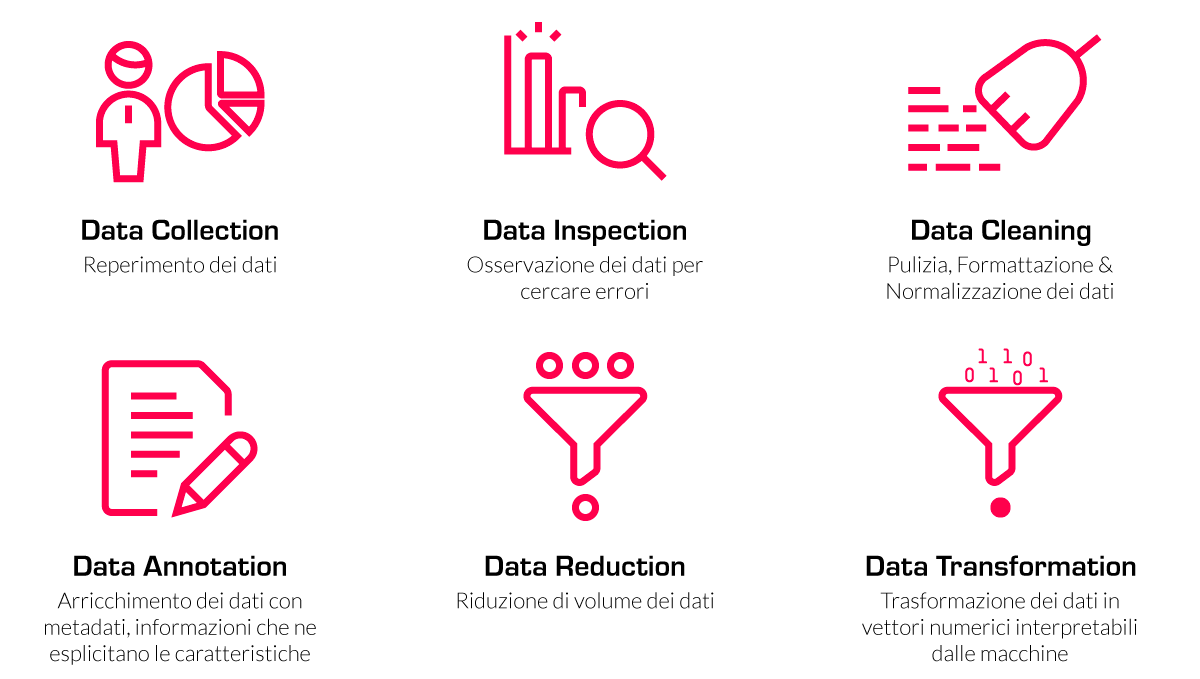
I passaggi standard che portano alla creazione di un dataset e al suo preprocessamento per task NLP sono quindi:
-
- Data Collection
- Data Inspection
- Data Cleaning
- Data Annotation
- Data Reduction
- Data Trasformation
Forti delle premesse sopra presentate, lo scopo di questo articolo è duplice:
- da una parte, approfondire il ruolo dei dati, insieme alle loro modalità di collezione e archiviazione;
- dall’altra, presentare gli step principali e gli strumenti che rendono possibile la prima fase di preprocessamento dei dati, il Data Cleaning.
Per garantire un approccio consapevole al NLP, nel trattare questi argomenti abbiamo adottato una modalità “critica”: strumenti e metodi verranno esposti con estratti di codice, esempi e considerazioni sulle procedure presentate.
Il ruolo dei dati nel Natural Language Processing
Come molti compiti computazionali di una certa complessità, anche i task NLP hanno trovato particolare giovamento dagli avanzamenti nel campo del ML, approccio che, come abbiamo visto, è alimentato e reso possibile dai dati. I dati in ML sono importanti per almeno tre ragioni:
- è attraverso i dati che si allena un algoritmo, ovvero un algoritmo impara ad eseguire un task;
- è attraverso i dati che si migliorano le capacità dell’algoritmo di fare inferenza sui dati;
- è attraverso i dati che si testa l’apprendimento dell’algoritmo: ovvero se esso è capace di eseguire lo stesso task su dati simili a quelli processati in fase di allenamento.
Nel caso del NLP, per dati si intendono dati linguistici: parole, frasi, testi sia in forma scritta che parlata appartenenti al linguaggio umano. I dati vengono raccolti in delle risorse, i corpus o dataset. Sebbene entrambi i termini vengano spesso usati come sinonimi per indicare una raccolta di dati linguistici, esiste una sottile differenza tra le due accezioni: un corpus diventa dataset nel momento in cui, tutto o una sua parte, viene scelto come fonte dati per un progetto NLP (nel resto dell’articolo utilizzeremo il termine dataset per riferirci alle collezioni di dati).
Durante il processo di costruzione di un dataset si devono tenere in considerazione quattro importanti fattori capaci di determinare la qualità del dataset stesso:
- Accuratezza: cercare di non includere dati che deviano da quelli aspettati.
- Completezza: assicurarsi che i dati raccolti siano sufficienti e rappresentativi del fenomeno che si vuole rappresentare.
- Consistenza: i dati, soprattutto se provengono da fonti diverse, devono essere uniformi.
- Interpretabilità: i dati devono essere comprensibili tanto dall’essere umano quanto dalla macchina che li processerà.
Dove trovare i dati adatti per un modello di NLP?
Quando si inizia un progetto NLP una delle prime domande che ci si pone è dove trovare i dati per allenare gli algoritmi. La risposta potrebbe sembrare facile, il web, soprattutto se si considera che viviamo in quella che viene comunemente chiamata l’era dei Big Data.
Secondo quanto riportato da Gartner Inc, infatti, entro il 2022 la quantità di dati prodotti dagli utenti web è destinata ad aumentare dell’800%. Tuttavia, si stima che l’80% di questi dati si troverà in forma non strutturata, ovvero privo di un modello di organizzazione predefinito che ne espliciti caratteristiche e relazioni. Il problema con questo tipo di dati e con il loro utilizzo in ML non risiede tanto nella loro quantità, quanto nella capacità di processarli in modo accurato, consistente e completo.
Per chi si affaccia per la prima volta al ML, potrebbe, quindi, risultare più congeniale fare affidamento ad una delle tante raccolte di dati create da enti pubblici o privati, disponibili sotto pagamento e/o licenze o come risorse aperte. In base alle condizioni imposte, è possibile, inoltre, arricchire queste risorse con metadati, ovvero con informazioni di qualche natura che potranno poi essere apprese dall’algoritmo.
Tuttavia, soprattutto nello sviluppo di modelli NLP da utilizzare all’interno di un ambiente aziendale, avere la possibilità di creare un dataset customizzato sulle proprie esigenze con all’interno i propri dati rappresenta il migliore investimento in termini di valore, accuratezza e performance. Nel resto dell’articolo si presenteranno i passaggi principali per seguire quest’ultima via.
“Conosci i tuoi dati”: il mantra da tenere a mente per costruire un dataset NLP efficiente
Passo fondamentale per creazione di un dataset è l’ispezione del dato che si sta per processare. Sebbene quasi tutti i dati necessitano di qualche forma di preprocessamento, è solo attraverso l’osservazione dei dati di cui si è in possesso che si possono scegliere le tecniche più adeguate. Per esempio, per pre-processare sia i dati in formato scritto sia parlato è buona prassi eliminare la parte di noisy data, ovvero quella parte di dati che in qualche modo corrompe e distorce la nostra collezione di dati. Tuttavia le modalità e le tecniche per eseguire questo step sono diverse nel caso di dato in forma scritta o parlata. Simili riflessioni si possono fare nel preprocessare lingue diverse: per evitare problemi di codifica, ad esempio, sarebbe utile trasformare alcune lettere dell’alfabeto tedesco – ä, ö, ü e ß – con forme meno “problematiche” – ae, oe, ue and ss – , modifica che non è invece necessaria nel caso dell’inglese.
Da dati non strutturati a dati semi-strutturati
Una volta individuati e ispezionati i dati che faranno parte del dataset, si può procedere con una serie di operazioni volte a trasformare i dati non-strutturati (vd. sopra) di partenza in dati semi-strutturati. I dati semi-strutturati si distinguono da quelli strutturati in quanto, pur seguendo un insieme di regole che ne determinano la classificazione, tali regole non sono né predefinite né fisse. Lo schema dei dati semi-strutturati è dunque flessibile e dinamico e si adatta perfettamente all’interpretazione dei dati linguistici. Infatti mentre risulterebbe sicuramente utile avere collocate informazioni quali titolo, autore, anno di pubblicazione di un testo di narrativa nelle celle di un database (il database è la modalità di archiviazione più diffusa dei dati strutturati), sarà poco conveniente disporre in questo formato il contenuto intero del testo. Tale strutturazione renderà infatti le informazioni contenute nel testo difficilmente accessibili alla macchina.
La possibilità di rendere interpretabili i dati testuali per una macchina è data dall’annotazione, ovvero dall’aggiunta di informazioni (metadati) ad un testo, capaci di esplicitarne qualche sua caratteristica. Il passaggio dal dato grezzo al dato annotato passa però da una tappa fondamentale di preprocessing: il Data Cleaning.
Data Cleaning: tecniche e strumenti

La regola “garbage in, garbage out” insegna che se i dati immessi in una macchina sono “sporchi”, i risultati che dobbiamo attenderci lo saranno altrettanto. Questa regola si applica anche ai dati linguistici, che, se in formato grezzo, potrebbero portare dei problemi da non sottovalutare in fase di processamento. Il Data Cleaning, fase di preprocessing che si occupa di eliminare informazioni non necessarie e, insieme, normalizzare, formattare e standardizzare i dati, si rivela perciò essere un passo fondamentale per garantire la qualità dei dati che verranno processati dall’algoritmo.
Per quanto essenziale questa fase possa essere, prima di scegliere una modalità o uno strumento di preprocessing è bene considerare, non solo i dati in possesso, ma anche il task che si vuole svolgere con quei dati. Per alcuni task una tecnica di cleaning può essere fortemente consigliata, se non addirittura obbligatoria, per altri se ne può fare a meno senza che venga compromessa l’accuratezza del modello finale.
Lista dei task di data cleaning:
-
- Rimozione dei noisy data
- Lowercasing
- Tokenizzazione: per farsi e per parole
- Eliminazione delle stopword
- Normalizzazione del testo
- Stemming
- Lemmatizzazione
La rimozione dei “noisy data”
Per rimozione dei “noisy data” (dati rumorosi) si intende l’eliminazione di caratteri non necessari come URL, tag HTML, caratteri non-ASCII, ecc che potrebbero interferire negativamente con l’analisi del testo. Così come per gli esseri umani, anche per le macchine infatti, la presenza di elementi fuori contesto o superflui rappresenta un ostacolo alla lettura e alla comprensione che potrebbe far sorgere ambiguità e problemi nelle fasi successive di processamento. Ma come si stabilisce che cosa è rumoroso e cosa no?L’entità degli elementi fastidiosi è altamente dipendente dai dati di partenza. Ad esempio, mentre il simbolo di hashtag (#) rappresenta un elemento di rumore nella maggior parte dei testi, non lo è nei tweet, dove per la funzione che svolge, assume un valore paragonabile a quello di un prefisso. Eliminare quel simbolo porterebbe, quindi, ad una perdita di significato. La pulizia dipende anche dal task e dalle applicazioni NLP: mentre i segni di punteggiatura possono non essere utili nella topic detection, sono fondamentali, invece, nei task di speech recognition, in quanto danno indicazioni su intonazione e cadenza del parlato.Di seguito verranno presentate alcune tecniche di rimozione dei noisy data. Data la variabilità degli elementi che possono essere eliminati, il metodo migliore per eseguire questo step sono le espressioni regolari (regex, supportate in python dalla libreria re), ovvero una sequenza di simboli che identificano una stringa, sulla quale è possibile eseguire azioni, come eliminazione, ricerca, sostituzione
Un esempio: rimozione di noyse data su Articolo 3 della Costituzione Italiana (con riferimenti)
text = “Tutti i cittadini hanno pari dignità sociale [cfr. XIV] e sono eguali davanti alla legge, senza distinzione di sesso [cfr. artt. 29 c. 2, 37 c. 1, 48 c. 1, 51 c. 1], di razza, di lingua [cfr. art. 6], di religione [cfr. artt. 8, 19], di opinioni politiche [cfr. art. 22], di condizioni personali e sociali.”
- Rimozione di tutte le cifre
import re
text_without_digits = re.sub(r’\d+’, ”, text)
Tutti i cittadini hanno pari dignità sociale [cfr. XIV] e sono eguali davanti alla legge, senza distinzione di sesso [cfr. artt. c. , c. , c. , c. ], di razza, di lingua [cfr. art. ], di religione [cfr. artt. , ], di opinioni politiche [cfr. art. ], di condizioni personali e sociali.
- Normalizzazione delle cifre: sostituzione delle cifre con “$”
import re
text_without_digits = re.sub(r’\d+‘, ‘$’, text)
Tutti i cittadini hanno pari dignità sociale [cfr. XIV] e sono eguali davanti alla legge, senza distinzione di sesso [cfr. artt. $ c. $, $ c. $, $ c. $, $ c. $], di razza, di lingua [cfr. art. $], di religione [cfr. artt. $, $], di opinioni politiche [cfr. art. $], di condizioni personali e sociali.
- Rimozione della punteggiatura
punctuation = "'!"#$%&'()*+,-./:;<=>?@[]^_`~"'
text_without_punctuation = "".join(i for i in text if not i in punctuation)
Tutti i cittadini hanno pari dignità sociale cfr XIV e sono eguali davanti alla legge senza distinzione di sesso cfr artt 29 c 2 37 c 1 48 c 1 51 c 1 di razza di lingua cfr art 6 di religione cfr artt 8 19 di opinioni politiche cfr art 22 di condizioni personali e sociali
Il Lowercasing
Convertire tutti i dati testuali da maiuscole in minuscole è uno dei più semplici passi che solitamente si eseguono in fase di preprocessing. Questa operazione risulta essere molto utile per eliminare distinzioni tra parole identiche nel loro significato ma che si distinguono graficamente per la presenza di lettere maiuscole. Infatti se la parola “rosa” comparisse in uno stesso dataset in differenti versioni (“Rosa”, “ROSA”, RosA”, “rosa”) potrebbe non essere scontato per un modello di machine learning identificarne tutte le occorrenze e collegarle ad un’unica entità.
text = “La Signora Rosa porta una gonna rosa.”
lowercased_text = text.lower()
output:
>> la signora rosa porta una gonna rosa.
Eseguito spesso come un task di default in fase di preprocessing, anche il lowercasing merita alcune considerazioni. Se il task prevedesse il riconoscimento dei nomi propri, potrebbe non essere utile convertire completamente le lettere sin da principio: se, come nell’esempio, “Rosa” fosse anche un cognome, mapparlo come “rosa” potrebbe generare ambiguità.
Tokenizzazione
Tokenizzare un testo significa suddividerlo in unità minime di analisi (chiamate token), che possono essere costituite da caratteri, cifre, parole, porzioni di frasi, intere frasi e qualunque altro elemento che abbia significato. La suddivisione in token rende possibili gli ulteriori step di preprocessamento che, altrimenti, risulterebbero complessi o inefficaci.
Una corretta tokenizzazione, così come la scelta dello strumento per tokenizzare, implica:
- stabilire le unità minime di analisi;
- stabilire dei criteri che definiscono il confine di parola.
Comunemente in fase di Data Cleaning per il NLP, il tokenizer viene utilizzato per suddividere il testo in frasi e, successivamente, in parole.
Tokenizzare per frasi
In questa fase di tokenizzazione, l’unità minima di analisi è la frase. Sebbene lo si possa considerare un task banale, l’individuazione di una frase in assenza di un’analisi sintattica/semantica non è scontata. La punteggiatura, che dovrebbe essere il tratto guida per la sua individuazione, può trarre in inganno: il punto, per esempio, può indicare certamente la fine di una frase, ma anche un’abbreviazione (Dott.), un acronimo (U.S.A.), il separatore di una cifra decimale (0.56) o di una data (15.02.2021). Allo stesso modo una lettera maiuscola può indicare l’inizio di una nuova frase ma anche un nome proprio.
Nell’esempio che segue è stata utilizzata la funzione sent_tokenize() messa a disposizione da NLTK (Python). Sent_tokenize() richiama di default (allo stato attuale) il PunktSentenceTokenizer. Questo sfrutta un algoritmo non supervisionato per individuare le abbreviazioni e gli elementi ad inizio frase e, sulla base di tale modello, suddividere il testo in frasi.
from nltk.tokenize import sent_tokenize
text = “Il sig. Rossi va sempre a lavoro con l’autobus n. 3. Usa la macchina solo in caso di emergenza”
sentence_tokenizer_output = sent_tokenize(text)
[“Il Sig. Rossi va sempre a lavoro con l’autobus n. 3.”, “Usa la macchina solo in caso di emergenza”]
La tokenizzazione in frasi non rappresenta una tappa sempre indispensabile in fase di preprocessing. Se, in nessuno dei momenti successivi, la frase in quanto tale risulta essere di interesse, è possibile bypassare questa fase e procedere direttamente con la tokenizzazione di un testo in parole. Se, ad esempio, il dataset è composto da una lista di parole, la tokenizzazione in frasi risulterà inutile.
Tokenizzare per parole
La suddivisione di un testo in “parole” è una tappa fondamentale del preprocessing, forse una delle poche, realmente necessarie in ogni contesto NLP. Il suo utilizzo apre a diverse analisi e task: da quelli di estrazione del vocabolario e calcolo della varianza lessicale a quelli di complessità superiore come la traduzione.
Prima di esplorare gli strumenti disponibili è bene, però, fare una premessa. Il termine parola viene usato, qui, impropriamente per indicare non solo le parole in senso stretto, ma anche caratteri numerici, segni di punteggiatura, sigle e abbreviazioni. Ci è sembrato sensato utilizzare tale termine per una somiglianza con il nome degli strumenti più comunemente utilizzati per il task.
Quali criteri adottare per tokenizzare in parole? In molte lingue lo spazio è un indicatore di segmentazione, ma da solo non è sufficiente. Alcuni casi della stessa lingua italiana, come “La Spezia”, in cui lo spazio non indica la presenza di due token o “l’arancia”, dove sono presenti 3 token seppur nessuno spazio, fanno capire come è necessario fare affidamento su altri criteri linguistici per tokenizzare.
Il pacchetto NLTK, offre la funzione word_tokenize() che usa come word tokenizer di default il TreebankWordTokenizer. Si tratta di un tokenizzatore che funziona tramite regex, ossia utilizza una serie di espressioni regolari come linea guida per operare la suddivisione del testo in token.
from nltk.tokenize import word_tokenize
text = “La città di La Spezia è in Liguria.”
word_tokenizer_output = word_tokenize(text)
[‘La’, ‘città’, ‘di’, ‘La’, ‘Spezia’, ‘è’, ‘in’, ‘Liguria’, ‘.’]
Dall’output del word_tokenizer() è possibile notare che la funzione non elimina la punteggiatura e che separa in due token distinti, elementi che indicano un’espressione unica. Il problema delle espressioni multi-parola rappresenta, in alcuni casi, un forte ostacolo alla corretta elaborazione dei contenuti. “La Spezia” o “Hot dog” assumono significati totalmente differenti se tokenizzati in modo scorretto.
Per gestire questo tipo di casi è possibile utilizzare il MWETokenizer di NLTK. Il MWETokenizer è un tokenizer che elabora il testo precedentemente tokenizzato (tramite word_tokenize(), ad esempio) e fonde le espressioni di più parole in token singoli.
from nltk.tokenize import MWETokenizer
text = ‘La città di La Spezia è in Liguria’
tokenizer = MWETokenizer()
tokenizer.add_mwe((‘La’, ‘Spezia’))
tokenized_text = tokenizer.tokenize(text.split())
output:
[‘La’, ‘città’, ‘di’, ‘La_Spezia’, ‘è’, ‘in’, ‘Liguria’]
I tokenizzatori disponibili non si esauriscono in quelli presentati sopra; tuttavia gli output che essi forniscono sono abbastanza corretti per cui si può pensare di utilizzarli in molti task NLP senza indugio.
Eliminazione delle stopword
Articoli, preposizioni, congiunzioni, avverbi sono esempi tipici di stopword, in generale parole che posseggono uno scarso contenuto semantico. Al pari degli elementi rumorosi, la loro presenza potrebbe interferire con il processamento del linguaggio, contribuendo a far distogliere l’attenzione dalle parole a più alto contenuto semantico.
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
tokenized_text = word_tokenize(“la sorella di Marco suona bene il piano”)
filtered_words = [token for token in tokenized_text if token not in stopwords.words(‘italian’)]
output:
[‘sorella’, ‘Marco’, ‘suona’, ‘bene’, ‘piano’]
L’eliminazione delle stopword giova, per esempio, alla topic detection e ai sistemi di ricerca, dove inserita una query del tipo “Lista di stopword in italiano”, essi si baseranno sulle parole “lista”, “stopword” e “italiano”, invece che su “di” e “in” per ricercare i documenti. In altri casi però, privare il testo delle stopword implicherebbe una radicale distorsione del significato:, la frase “Il Grande Fratello è nato nel 2001” diventerebbe “Fratello è nato 2001”, che non è per nulla uguale a quello che si intendeva in partenza.
Il consiglio, nel caso si ritenga che l’eliminazione delle stopword possa portare benefici al task, è quello di customizzare la lista di stopword che si vuole usare.
Normalizzazione del testo
Normalizzare un testo consiste nel ricondurre alcune parole alla loro forma canonica “bellloooo”–> “bello”, in caso di errori (“propio”–>”proprio”), abbreviazioni (“cmq”–>”comunque”) o in presenza di parole quasi identiche (“pre-processing”, “preprocessing”, “pre processing”). Questa tecnica è molto utile soprattutto quando si preprocessano dati linguistici provenienti dai social network, sms o blog in cui è più frequente l’uso di queste espressioni. La normalizzazione può incidere sulle prestazioni dell’algoritmo di allenamento in quanto risolve problemi di sparsità dei dati.
Come nel caso del rumore, gli elementi da normalizzare dipendono dal task e dai dati. Anche le tecniche da utilizzare variano molto: si passa da approcci basati sulla mappatura in dizionari o su quelli basati su correttori automatici.
Lo Stemming
Lo stemming è il processo di riduzione di una parola alla sua radice, dove per radice non si intende per forza una parola del vocabolario, la forma base, ma più che altro una forma canonica della parola originaria. Per esempio, le parole “giardino”, “giardini” o “giardinaggio” condividono la stessa radice, “giardin”.
L’algoritmo di stemming più comune è il PorterStemmer, nato negli anni ‘80 e particolarmente efficace per la lingua inglese:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
stems = stemmer.stem(“was”)
output:
>> wa
Esistono altri due algoritmi rilevanti per lo stemming: lo SnowStemmer e il LancasterStemmer. Il primo è un’evoluzione del PorteStemmer ed è molto simile ad esso. Il LancasterStemmer, è invece, più aggressivo dei precedenti e va usato con attenzione poiché potrebbe produrre output anomali.
Stemming sì, stemming no?
Come in ogni caso, dipende dal task. Lo stemming può sicuramente aiutare in casi di sparsità dei dati o, in generale, per standardizzarli. Tuttavia, la “crudeltà” con cui effettua i tagli sulle parole suggerisce di utilizzarlo con attenzione in fase di preprocessing.
La Lemmatizzazione
La lemmatizzazione è un’operazione molto simile allo stemming, sebbene la radice che si ottiene è la forma base, il lemma. La lemmatizzazione non usa euristiche o regole predefinite per ottenere la radice, ma fa riferimento al contesto e a regole lessicali
In NLP, si fa solitamente affidamento a un dizionario come WordNet per le mappature o ad approcci speciali basati su regole. Ecco un esempio di lemmatizzazione in azione usando un approccio basato su WordNet:
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
lemmatizer = WordNetLemmatizer()
lemma = lemmatizer.lemmatize(“was”, wordnet.VERB)
output:
>> be
Sebbene il tipo di analisi offerto dalla lemmatizzazione possa considerarsi più corretto a livello linguistico rispetto allo stemming, il suo utilizzo sottostà alle stesse considerazioni fatte per lo stemming. In aggiunta a queste, va notato che in alcuni casi la lemmatizzazione può rallentare il preprocessing di un testo, in quanto per eseguirla in modo corretto è necessario che ai token venga assegnata una classe grammaticale.
Considerazioni finali
Nell’articolo abbiamo presentato in modo critico le prime fasi di creazione di un dataset per il NLP, soffermandoci soprattutto sulla fase di pulizia dei dati. Abbiamo visto come non tutti i task NLP richiedono lo stesso livello di pulizia e quanto inserire livelli di pulizia non utili possa creare problemi, invece di soluzioni.
Nonostante la loro inequivocabile importanza, la raccolta e la pulizia dei dati vengono, spesso, presentate come le parti meno “attraenti” del processo di sviluppo di un modello NLP. Ed è invece solo prestando la giusta attenzione a queste fasi, alla struttura della risorsa, al tipo di dati che è al suo interno e a come questi sono stati puliti e, successivamente, strutturati che si può stimare la scalabilità di un dataset, predire prestazioni e limiti di un modello, progettare interventi mirati in caso di calo delle performance. Se paragonassimo la costruzione di un modello ad viaggio da un polo all’altro della Terra, pianificare e conseguire una corretta pulizia dei dati significherebbe trovarsi già più giù dell’Equatore.